Handling DynamoDB TTL expiry events with AWS Lambda and DynamoDB Streams
... responding to the uneventful progress of time
There are plenty of ways to build software that responds to changes in data or outside events. It can be less intuitive to come up with a solution that needs to respond to nothing happening.
1. Problem: Abandoned shopping cart
As part of a team working in the domain of customer journeys involving a shopping cart, I was once approached by a team of the marketing department with a request. The request was whether we could help them reach customers who, for whatever reason, left the website after putting products in their shopping cart, never placing an order. This phenomenon is referred to as an Abandoned Cart.
My team was a full stack development team, meaning we took care of infrastructure, backend & frontend development, UX, monitoring and customer feedback on the features we delivered.
Given that my team was in the business of creating and maintaining carts up until the point of purchase, it made sense they came to us. But we were not in the habit of keeping track of which carts were abandoned; none of our features demanded it. Thus, we had to define what was considered to be an abandoned cart, and in order to distill that information, we had to create it.
2. Constraints and requirements
Even though the Abandoned Cart business case touches on both our domains, some boundaries were clear:
-
We would not be reaching out to customers. The marketing team would do that.
-
Marketing would not go digging in our database. That would be tight coupling that would either cripple our ability to change our most valuable data model in the future, or break the dependent functionality of the marketing team. If we had the data to give them, we would be giving it.
Other boundaries were less clear, but became evident as we explored possible solutions.
3. Solution: Rejected approaches
3.1. Just share your events with others
The first people to approach us with this problem were aware of a solution that had been implemented in the past. It was a separate application, running on its own AWS EC2 instance in ECS, and it would receive all changes to a shopping cart via an AWS SNS / SQS pub sub mechanism. Changes included adding a product, removing a product, going from anonymous to logged in customer, adding a delivery address, and so forth. This separate application would then figure out when a given cart was to be considered abandoned, and sent out an email.
This application by now had been decommissioned, and the bit where customers can be contacted has since moved to a COTS marketing suite.
The first assumption by people involved in that project was therefore to simply start sending out those same cart update events to that new marketing suite via SNS / SQS.
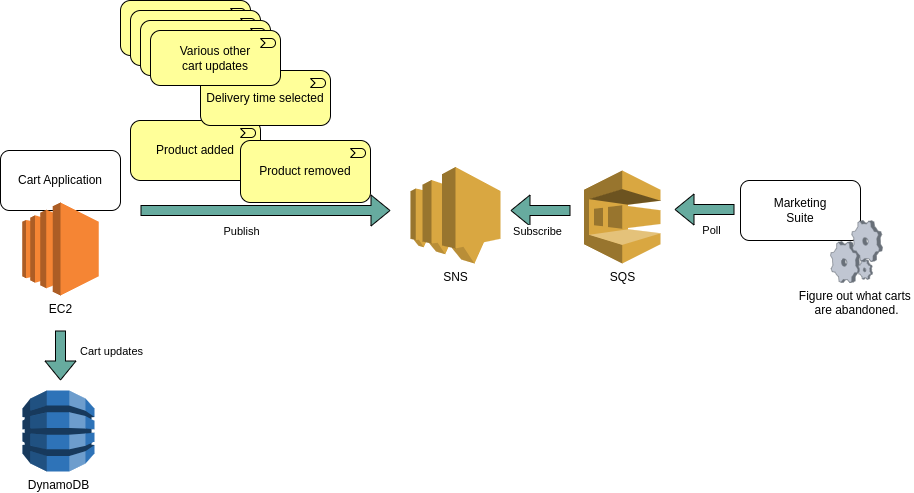
Considering this approach, several new constraints and requirements popped up.
-
The marketing suite did not offer a great degree of modification. It was in fact not an option to have the marketing suite poll an SQS queue. We would have to be a conformist to their API.
-
We could place the SQS in our own repository and introduce an application that could poll it and then make the calls to that API, as a sort of Anti-corruption layer. But we felt that would be too many moving parts; it would be better to simply have our cart application make some asynchronous calls to the API.
-
The responsibility boundary (or bounded context) became more clear: it didn’t make sense to send all those shopping cart changes to another domain, and to expect them to interpret all that information, most of which was irrelevant to them and their use case. That interpretation was business logic that belonged in our own domain.
So we came to the following guiding constraints:
-
We would be keeping track of which shopping cart was considered abandoned.
-
We would only send abandoned shopping cart information to the marketing team.
-
We wouldn’t use a pub/sub architecture.
3.2. Tag your data with lastmodified info and scan intermittently
Given that we were already storing shopping cart information in a database, the next intuitive approach was to simply enrich that information with a 'lastmodified' field, and have a scheduled job read that table to find records - shopping carts - that hadn’t been modified recently, and send those as a batch to the marketing suite.
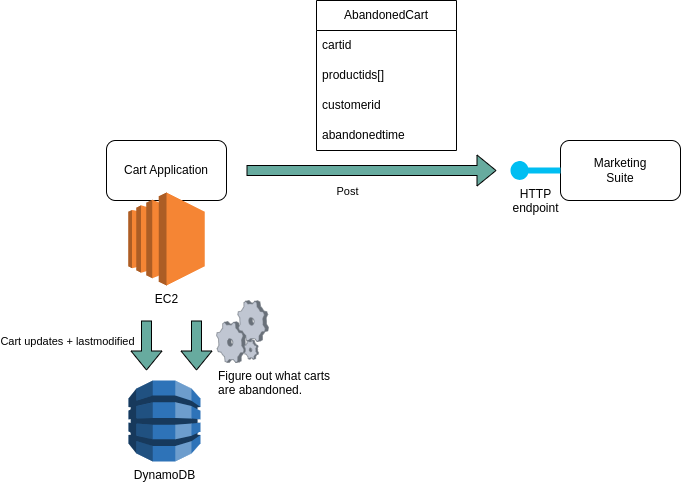
Again, diving deeper, we quickly stumbled on more constraints and insights:
-
Having worked in projects hampered by tightly coupled implementations, we felt we were about to step into a pitfall. Overeager and premature normalization of data models with similar names can hurt, once it becomes clear that different use cases result in different directions for the evolution of your data model. Simply put: knowing and acting on which carts are abandoned is a different use case than that of a customer assembling a list of products to buy. They’re related, but shouldn’t be tightly coupled. Enriching existing data models with flags for new interpretations is often a red… flag.
-
The shopping cart data was stored in a DynamoDB table, which was a fine fit for its existing use. It is, however, a NoSQL solution, which means you can’t just go about querying a table on arbitrary fields. You can have a partition key and a sort key, and, confirming our suspicion in the previous point, those were already tailored to a different use case.
-
Querying a DynamoDB table repeatedly to find records that have a lastmodified older than X hours costs money. You could do it less often to avoid the cost, but clearly, this wasn’t ideal.
New ideas popped up:
-
Create a separate DynamoDB table for cart activity, containing only the information needed to inform marketing.
-
Figure out a way to detect automatically when such a record hasn’t been updated recently.
4. Solution: Accepted approach
It was that last idea that got me thinking about the language we had been using to describe the problem.
Abandoned…
Stale…
Expired!
Of course! A DynamoDB can mark a record as expired! We don’t have to build logic to check for this ourselves!
You configure this on a DynamoDB table via a Time To Live (TTL) setting. You designate a field on your data record to be the indicator; then you set that field on creation and update it whenever you update the record. And as described in the AWS documentation:
After you enable TTL on a table, a per-partition scanner background process automatically and continuously evaluates the expiry status of items in the table. [..] A second background process scans for expired items and deletes them. Both processes take place automatically in the background, do not affect read or write traffic to the table, and do not have a monetary cost.
Furthermore:
As items are deleted from the table, two background operations happen simultaneously: Items are removed from any local secondary index and global secondary index in the same way as a DeleteItem operation. This operation comes at no extra cost. A delete operation for each item enters the DynamoDB Stream, but is tagged as a system delete and not a regular delete.
So, not only could we use DynamoDB TTL-based expiry to detect when there had been no cart activity for a defined amount of time, but the expired data record would then be automatically removed from the table and sent into a DynamoDB stream, all at no cost.
This had some technical implications:
-
Once expired, a record is deleted, so future action cannot be taken. This was fine for our use case.
-
Although our tests showed immediate response upon expiry, the TTL scanning process isn’t guaranteed to be immediate. It might take up to two days, depending on other activity on your table. This too was acceptable for our use case, which is sending someone a reminder after an arbitrary period of inactivity.
So this seemed like an angle to pursue.
Now up until now, we had been considering where the implementation logic should go for querying a database and contacting the marketing suite:
-
Our cart application
-
The marketing suite
-
A separate application
Given that extracting exactly the right data was already taken care of by DynamoDB, the remaining bit to implement was simply "respond to the expiry event, read the data, transform it, and send it to the marketing suite". When you’re on AWS and you think "respond to an event", AWS Lambda comes to mind. And wouldn’t you know it: The best part about being able to use DynamoDB and DynamoDB Stream like this, is that it is a valid eventsource for AWS Lambda.
Our architecture ended up looking like this:
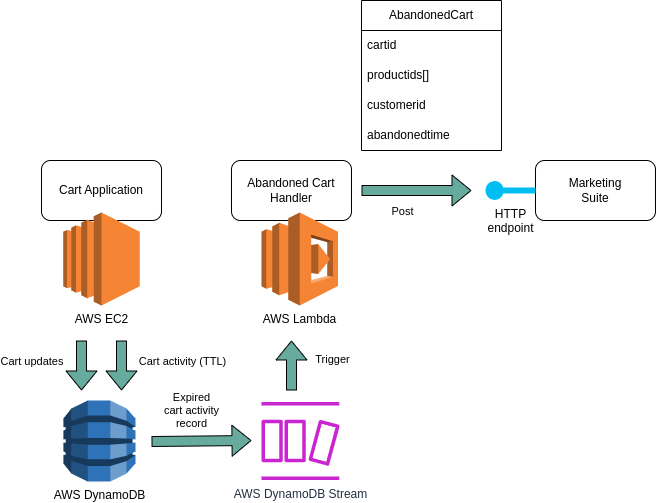
Our Terraform code involved the following bits:
A fragment of the DynamoDB table in the main cart application, where it stored only those bits of information required for reminding a customer of products they didn’t order.
resource "aws_dynamodb_table" "cartapplication_cartactivity" {
name = "cartapplication_cartactivity"
hash_key = "cartid"
stream_enabled = true
stream_view_type = "NEW_AND_OLD_IMAGES"
ttl {
enabled = true
attribute_name = "ttl"
}
attribute {
name = "cartid"
type = "S"
}
attribute {
name = "productids"
type = "SS"
}
attribute {
name = "customerid"
type = "S"
}
attribute {
name = "ttl"
type = "N"
}
}DynamoDB knows S for String, SS for a set of Strings, and an N for a number, but also stored as a String.
Importantly, whatever field you mark as the TTL field for your table should contain a date in epochseconds format.
I will not list the implementation code that updates these records at various points. A particular thing to note, is that if a customer places an order, the record is deleted entirely. That is a different kind of removal than a system removal that the DynamoDB expiry scanner performs. That is relevant, because we’re only interested in carts that were really abandoned. More on that later.
A thing to also note, is that our table only contained references to customer and products; we didn’t own that data, and so we didn’t provide it. In event driven architecture, it’s good to check whether that’s a good enough guard of referential integrity. Imagine that the entity behind the productid or behind the customerid can change, and it’s important to refer to the state of that entity at a particular moment in time: then simply providing these reference might not be good enough. But it sufficed in our use case.
Now for reasons I won’t go into here, the Lambda function code and its Terraform code had to be placed into a separate repository from the cart application. That is not a problem per se, but because it’s not uncommon, I’ll mention that this meant that in our Lambda Terraform code, we had to create a data source referencing the DynamoDB table. That way, we could then refer to this data source to find the DynamoDB table’s Stream ARN.
data "aws_dynamodb_table" "cartactivity-table" {
name = "cartapplication_cartactivity"
}A relevant fragment of the Lambda function definition:
resource "aws_lambda_function" "abandoned-cart-function" {
runtime = var.lambda_runtime
function_name = "my-abandoned-cart-function"
handler = "com.jdriven.function.adapters.lambda.AbandonedCartHandler"The event source mapping, tying the abovementioned DynamoDB Stream and Lambda function together:
resource "aws_lambda_event_source_mapping" "abandoned-cart-function_event-source-mapping" {
event_source_arn = data.aws_dynamodb_table.cartactivity-table.stream_arn
function_name = aws_lambda_function.abandoned-cart-function.function_name
filter_criteria {
filter {
pattern = jsonencode({
"userIdentity" : {
"type" : ["Service"]
"principalId" : ["dynamodb.amazonaws.com"]
}
})
}
}
starting_position = "TRIM_HORIZON"
maximum_retry_attempts = 1
bisect_batch_on_function_error = true
enabled = true
}The filter_criteria bit is where we restrict which specific DynamoDB events should trigger the Lambda; the rest will be ignored.
Note, that this has no effect on what actually happened in the DynamoDB table; it only determines what you’re interested in.
In the above Terraform snippet, the userIdentity bit in the pattern is how to describe a DynamoDB System event, like the DynamoDB expiry process.
And the Lambda function Kotlin code boiled down to this.
class AbandonedCartHandler() : RequestHandler<DynamodbEvent, Void> {
private val abandonedCartService: AbandonedCartService = AbandonedCartService()
// Entrypoint for Lambda function call
override fun handleRequest(dynamodbEvent: DynamodbEvent, context: Context): Void? {
dynamodbEvent.records.filter { shouldHandle(it) }
.forEach {
val abandonedCartData = toAbandonedCartData(it)
when (val result = abandonedCartService.processAbandonedCart(abandonedCartData)) {
is MarketingSuiteClient.Result.Success -> logRequestOk(abandonedCartData)
is MarketingSuiteClient.Result.Failure -> logRequestNotOk(result.response, abandonedCartData)
}
}
return null
}
private fun shouldHandle(record: DynamodbEvent.DynamodbStreamRecord): Boolean {
// Only handle DynamoDB TTL events. Redundant; filter_criteria on the eventsource in Terraform/AWS check this first & better.
return (
record.userIdentity?.principalId == "dynamodb.amazonaws.com" ||
record.userIdentity?.type == "Service"
) &&
record.eventName == "REMOVE"
}
// Read DynamoDB record and turn into internal data object
private fun toAbandonedCartData(record: DynamodbEvent.DynamodbStreamRecord): AbandonedCartData {
return AbandonedCartData(
uid = record.dynamodb.oldImage["uid"]?.s ?: "",
skus = record.dynamodb.oldImage["productids"]?.ss?.toSet(),
customeruid = record.dynamodb.oldImage["customerid"]?.s,
ttl = record.dynamodb.oldImage["ttl"]?.n?.toLongOrNull(),
)
}The rest of the Lambda code involved logging and calling the marketing suite.
The code comment in the shouldHandle() method refers to the filter_criteria mentioned earlier.
I’ll elaborate on that in the next section, on improvements.
This was pretty much it: Small, loosely coupled, few moving parts, and all the complicated bits managed by AWS.
5. Solution: Improvements
Once we had the solution running, we discovered there was room for improvement.
5.1. No unnecessary Lambda startups
We were storing cart activity data in a separate table, with information like customerId and productIds.
Each and every one of those table updates were DynamoDB events that would trigger the Lambda.
We were clever enough to build a shouldHandle() method in the Lambda to avoid parsing irrelevant information before sending it to the marketing suite, but that’s really too late: the Lambda has already run.
Running a Lambda costs money.
Using a Lambda for a use case that requires it to run all the time, means you’ve just implemented a very expensive server.
It’s better to finetune the filter_criteria of the DynamoDB Stream eventsource triggering the Lambda.
In our case, we managed to reduce the amount of times Lambdas were invoked unjustly from 94% to 0% by expanding the abovementioned filter_criteria to this:
filter_criteria {
filter {
pattern = jsonencode({
"userIdentity" : {
"type" : ["Service"]
"principalId" : ["dynamodb.amazonaws.com"]
},
"dynamodb" : {
"OldImage" : {
"productids" : {
"SS" : [{ "exists" : true }]
},
"customerid" : {
"S" : [{ "exists" : true }]
}
}
}
})
}
}This says:
-
Only trigger on DynamoDB system events, AND
-
Only trigger on records that have a customerId set, AND
-
Only trigger on records that have productIds set
5.2. Startup optimization
We mostly use Kotlin in our codebase, and it’s a given that the scale-from-zero cold startup times of JVM-based Lambdas can go up to several seconds. This decreased performance, which didn’t pose much of a functional problem for our use case. It also increases running time of the Lambda though, which costs money, which usually is an issue.
There are several ways to deal with this:
-
Use AWS SnapStart to cache a snapshot of a running Lambda just after initialization, to speed up future cold starts.
-
Pass
-XX:+TieredCompilationand-XX:TieredStopAtLevel=1parameters to the Java application, to limit Just-In-Time (JIT) compilation to C1. Further code optimization has performance overhead, while the short-lived Lambda application isn’t likely to benefit from the yielded further optimization. This would make the Lambda function declaration look like this:
resource "aws_lambda_function" "abandoned-cart-function" {
runtime = var.lambda_runtime
function_name = "my-abandoned-cart-function"
handler = "com.jdriven.function.adapters.lambda.AbandonedCartHandler"
environment {
variables = {
JAVA_TOOL_OPTIONS = "-XX:+TieredCompilation -XX:TieredStopAtLevel=1"
}
}-
Look at GraalVM based Ahead-Of-Time (AOT) solutions to create applications optimized for Lambda startup time.
6. Glossary
-
AWS SNS/SQS PubSub: A mechanism where application A publishes notifications of changes to AWS SNS, and application B subsribes to those notification events via AWS SQS, which it regularly polls.
-
COTS: Commercial Off The Shelf software package, commonly used for generic subdomains where buying standard specialized software is preferred to investing in custom built software.
-
Conformist: Domain Driven Design (DDD) context mapping concept to describe the situation where one application (or a bounded context) needs to conform to another’s preferred form of communication in order to communicate with it.
-
Anti-corruption layer: DDD context mapping concept to describe a layer that "protects" an application’s inner data model and language, by preventing the language and data models required for communicating with another application from seeping through into its own internal logic.
-
Lambda Cold startup time: AWS Lambda is called serverless compute because when it isn’t active, it’s not running any server. However, when it needs to run an application, it does indeed fire up a server. Under the hood, this server stays at the ready for a while, to be reused if the Lambda is triggered soon after, allowing for faster startup. After a period of inactivity, this server is disposed of. Any time a Lambda has to perform a "cold start", there is a noticaeble delay for Lambda running JVM-based functions.
